Aizaz Sharif
AI Expert, Computer Science Major, and a Philomath.

I am Aizaz Sharif, a computer Science Major, AI Engineer, and Researcher in Oslo, Norway. As a Machine Learning Engineer at AI Dev Lab, I build end-to-end LLM architectures while previously researching autonomous driving systems at the VIAS department of Simula Research Laboratory and the University of Oslo.
You can download my resume from here: Aizaz Sharif Resume
What I’m Building Now
At AI Dev Lab, I’m implementing a production-ready LLM-powered platform (app.saleskik.ai) for processing daily meeting recordings. This involves:
- Developing custom RAG solutions using LangChain, LangGraph, and Pinecone
- Building robust backend infrastructure with Python, Firebase, and Google Cloud services
- Creating intelligent conversation processing pipelines for context-aware meeting summarization
- Managing the full ML/LLM development lifecycle from prototyping to production
Scientific Contributions
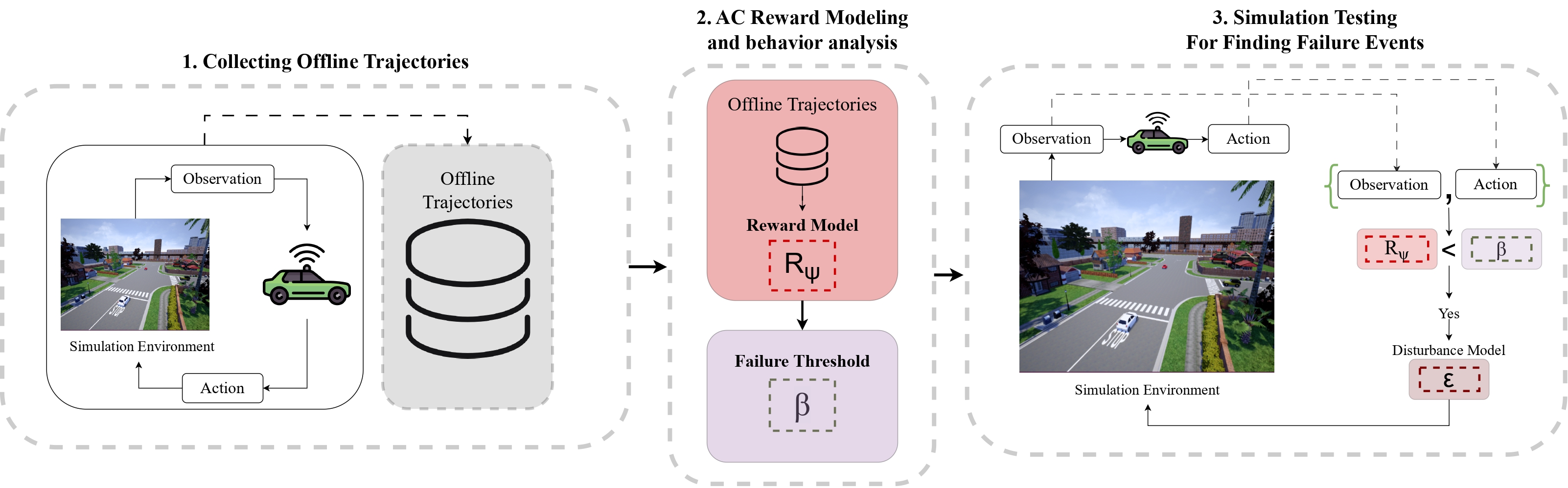
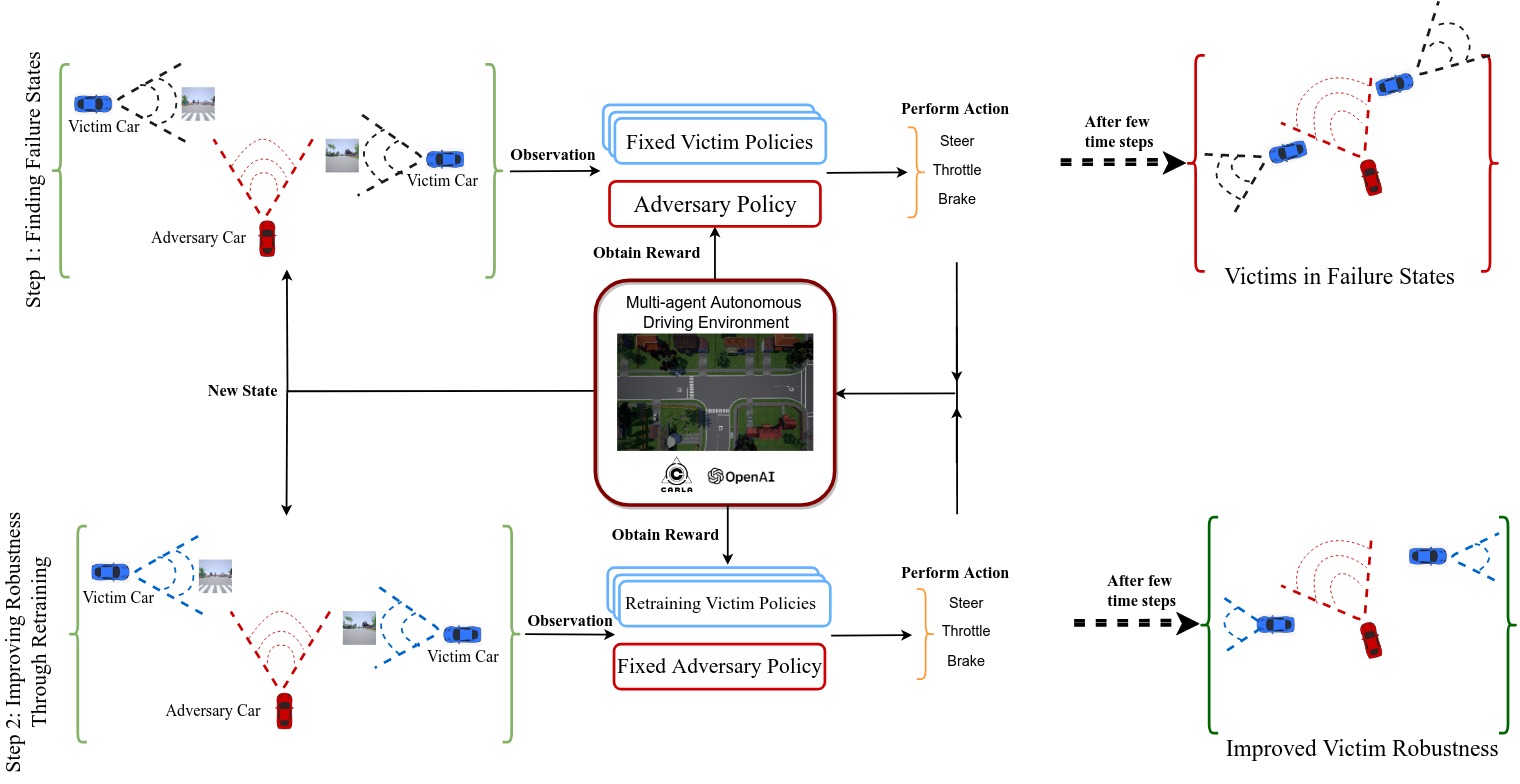
My doctoral research (defended on September 2024) focused on “Testing the Safety and Robustness of Autonomous Cars in a Multi-agent Environment,” where I made three novel scientific contributions:
- Adversarial reinforcement learning techniques for testing and improving autonomous systems
- Systematic benchmarking methodologies for multi-agent RL driving policies
- Reward modeling frameworks for finding uncertain state space without adversarial training approach
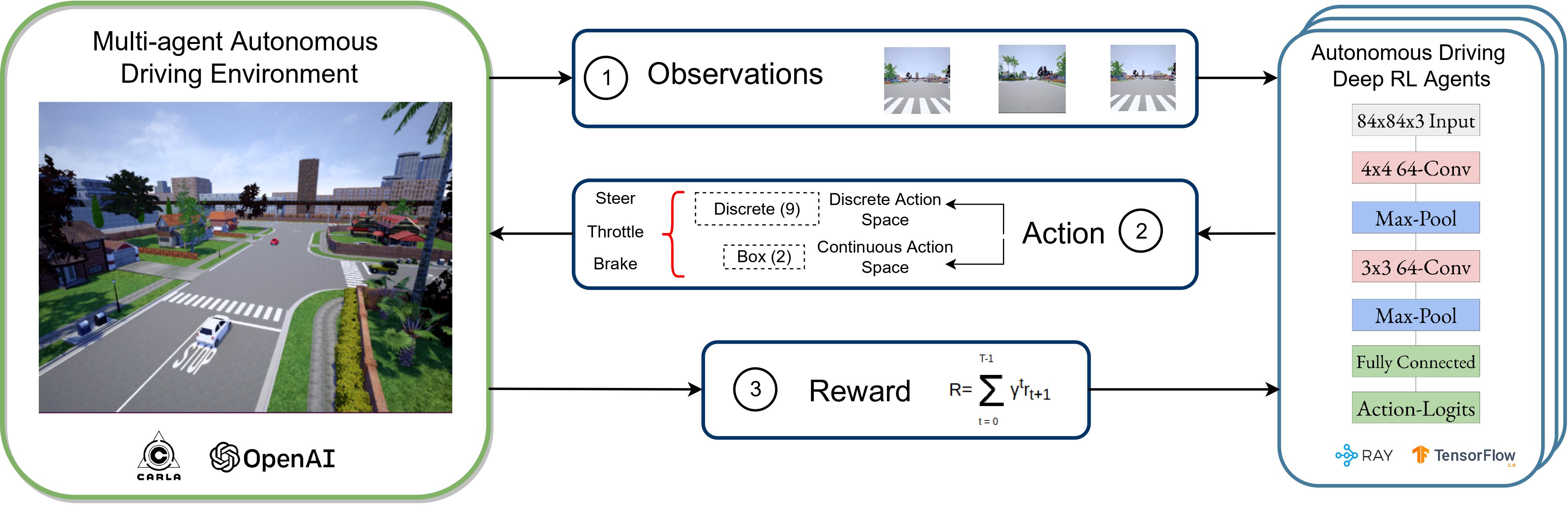
I’ve created and open-sourced platforms for testing multi-agent autonomous driving systems, gaining extensive experience with simulated driving environments and reinforcement learning.
Beyond autonomous driving, I have also performed research in medical imaging, Android security, and software engineering which resulted in multiple publications, including two conference papers and a journal article. This diverse research background has strengthened my ability to apply machine learning techniques across various domains.
Project Ownership & Team Leadership
I’ve successfully led teams and managed complex technical projects throughout my career:
- At Simula, I independently managed my entire research portfolio, from literature review to conceptualizing novel ideas, executing experiments, analyzing results, and writing papers - all while working autonomously to deliver high-quality scientific contributions
- At NCCS, I led a team developing a ‘Mobile Phone Digital Forensics’ toolkit, overseeing the entire project lifecycle from concept to beta testing with authorities
- At AI Dev LAb, I managed end-to-end ML/LLM development workflows and coordinated with cross-functional teams to deliver production-ready AI solutions. I also collaborated directly with clients to understand business requirements and translate them into technical solutions
Life Outside Code
Outside of my professional life, I enjoy photography and staying active through cycling, table tennis, and squash. I’m an enthusiastic Tekken player trying to compete at a higher level, and occasionally play other games like Rainbow Six Siege when time allows. I have a curiosity for learning about different cultures and collecting random facts. Living in Norway, I’m exploring the country’s beautiful landscapes and diverse regions, as well as engaging in travel photography during my adventures.
Contact
For collaboration, future opportunities, or any queries regarding my current or past work, you can reach out using my email: aizazsharif@gmail.com and LinkedIn.
news
| Apr 23, 2025 | Moved to a new website theme. Now completing unfinished blogs (both technical and memoirs). |
|---|---|
| Sep 27, 2024 | Defended my PhD thesis |
| Jan 11, 2023 | Blessed with a baby boy! |