publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2024
2022
-
 Adversarial Deep Reinforcement Learning for Improving the Robustness of Multi-agent Autonomous Driving PoliciesAizaz Sharif and Dusica MarijanIn 2022 29th Asia-Pacific Software Engineering Conference (APSEC), 2022
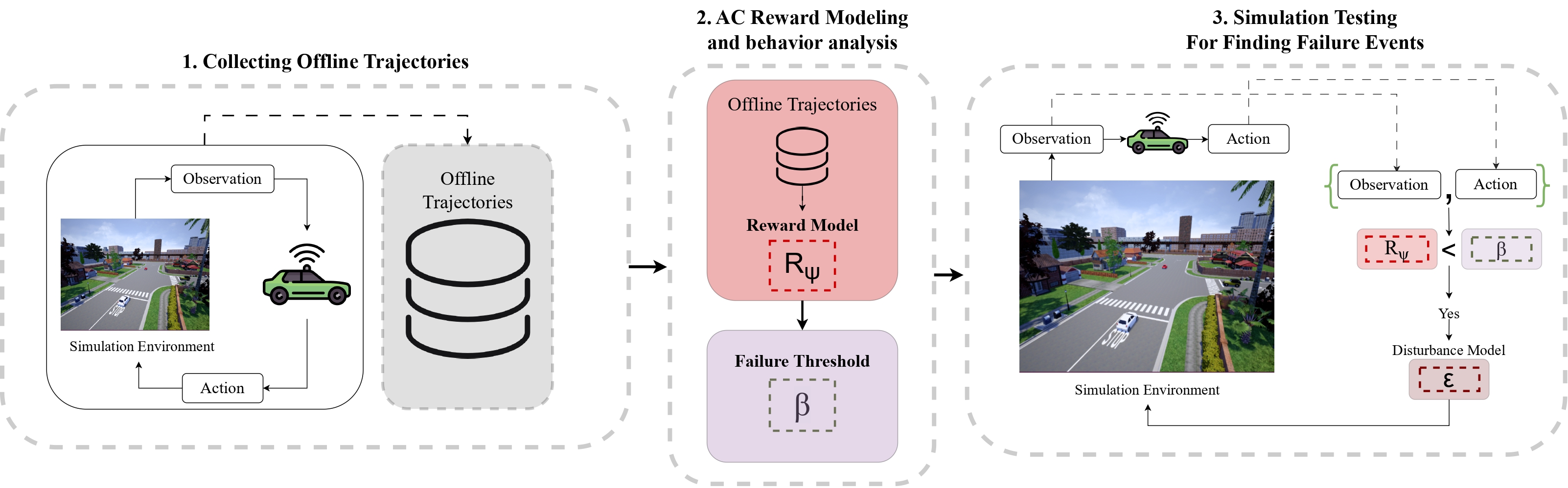
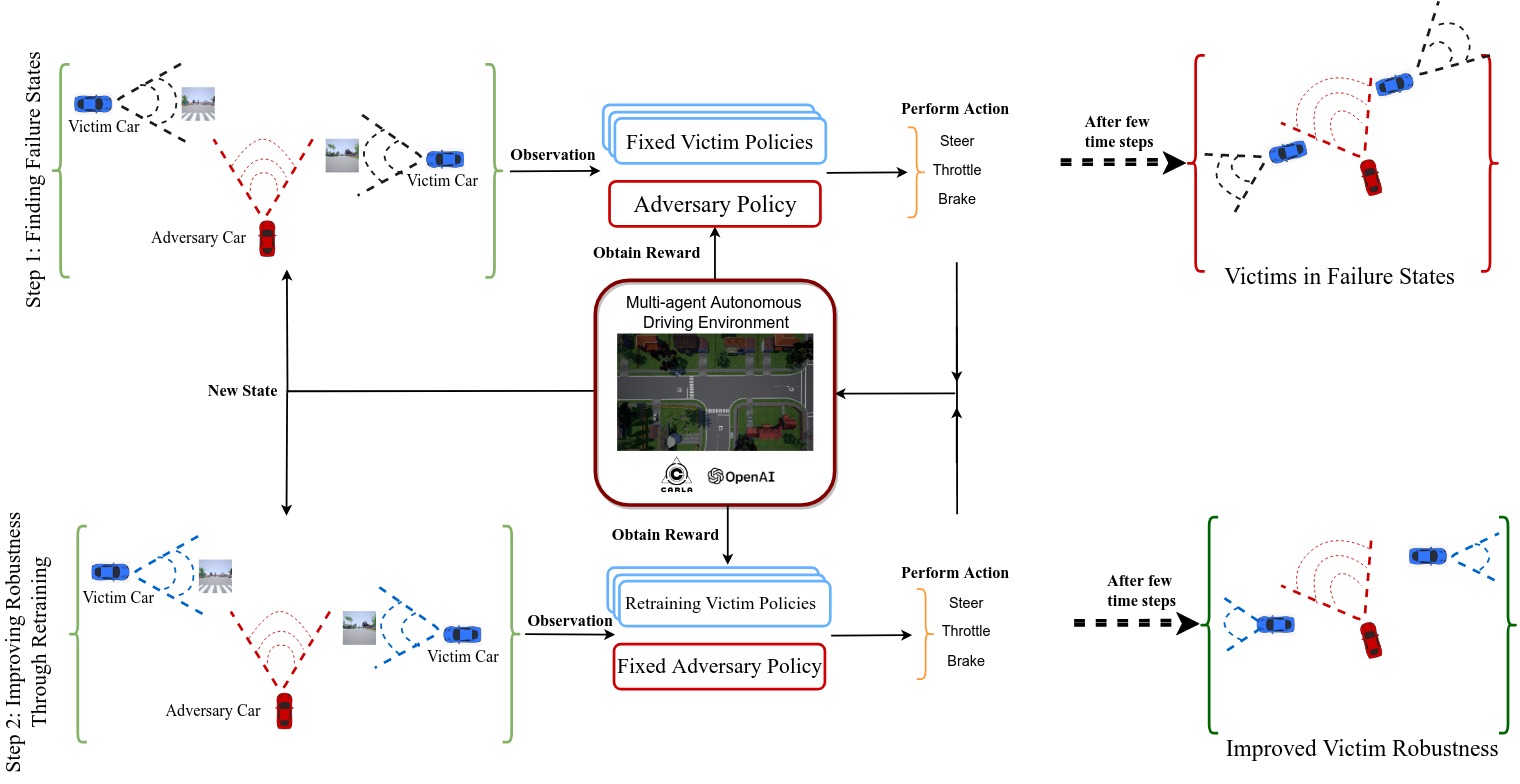
Adversarial Deep Reinforcement Learning for Improving the Robustness of Multi-agent Autonomous Driving PoliciesAizaz Sharif and Dusica MarijanIn 2022 29th Asia-Pacific Software Engineering Conference (APSEC), 2022Autonomous cars are well known for being vulnerable to adversarial attacks that can compromise the safety of the car and pose danger to other road users. To effectively defend against adversaries, it is required to not only test autonomous cars for finding driving errors but to improve the robustness of the cars to these errors. To this end, in this paper, we propose a two-step methodology for autonomous cars that consists of (i) finding failure states in autonomous cars by training the adversarial driving agent, and (ii) improving the robustness of autonomous cars by retraining them with effective adversarial inputs. Our methodology supports testing autonomous cars in a multi-agent environment, where we train and compare adversarial car policy on two custom reward functions to test the driving control decision of autonomous cars. We run experiments in a vision-based high-fidelity urban driving simulated environment. Our results show that adversarial testing can be used for finding erroneous autonomous driving behavior, followed by adversarial training for improving the robustness of deep reinforcement learning-based autonomous driving policies. We demonstrate that the autonomous cars retrained using the effective adversarial inputs noticeably increase the performance of their driving policies in terms of reduced collision and offroad steering errors.
-
 Evaluating the Robustness of Deep Reinforcement Learning for Autonomous Policies in a Multi-Agent Urban Driving EnvironmentAizaz Sharif and Dusica MarijanIn 2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS), 2022
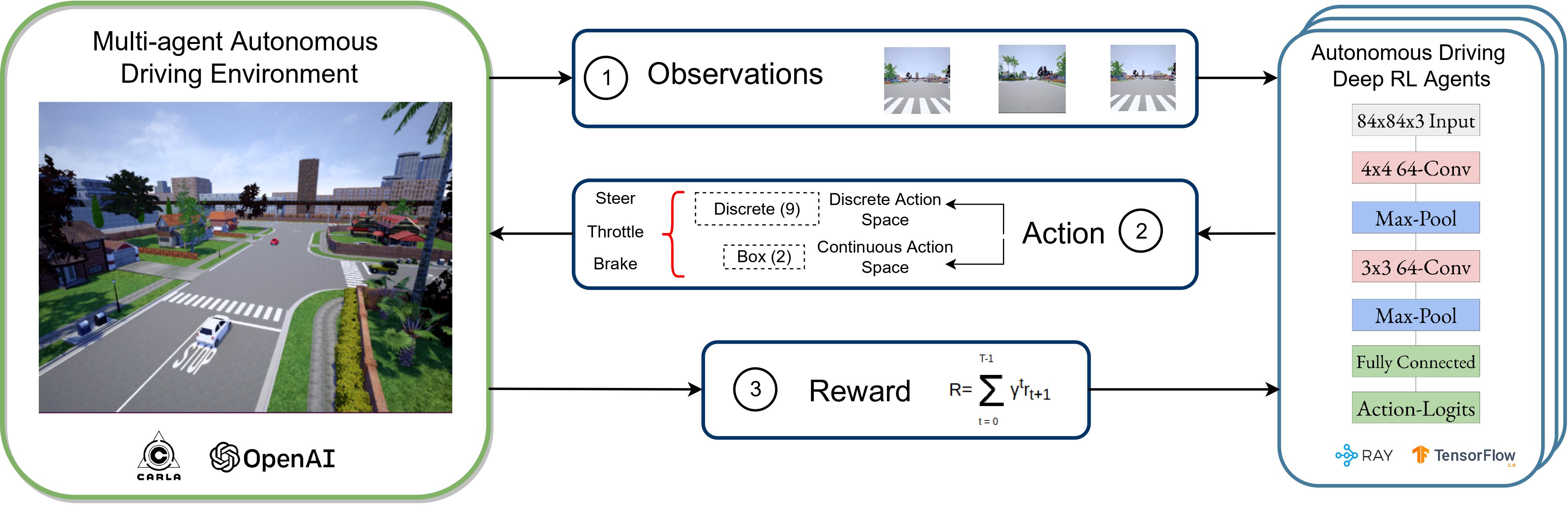
Evaluating the Robustness of Deep Reinforcement Learning for Autonomous Policies in a Multi-Agent Urban Driving EnvironmentAizaz Sharif and Dusica MarijanIn 2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS), 2022Background: Deep reinforcement learning is actively used for training autonomous car policies in a simulated driving environment. Due to the large availability of various reinforcement learning algorithms and the lack of their systematic comparison across different driving scenarios, we are unsure of which ones are more effective for training autonomous car software in single-agent as well as multi-agent driving environments. Aims: A benchmarking framework for the comparison of deep reinforcement learning in a vision-based autonomous driving will open up the possibilities for training better autonomous car driving policies. Method: To address these challenges, we provide an open and reusable benchmarking framework for systematic evaluation and comparative analysis of deep reinforcement learning algorithms for autonomous driving in a single- and multi-agent environment. Using the framework, we perform a comparative study of four discrete and two continuous action space deep reinforcement learning algorithms. We also propose a comprehensive multi-objective reward function designed for the evaluation of deep reinforcement learning-based autonomous driving agents. We run the experiments in a vision-only high-fidelity urban driving simulated environments. Results: The results indicate that only some of the deep reinforcement learning algorithms perform consistently better across single and multi-agent scenarios when trained in various multi-agent-only environment settings. For example, A3C- and TD3-based autonomous cars perform comparatively better in terms of more robust actions and minimal driving errors in both single and multi-agent scenarios. Conclusions: We conclude that different deep reinforcement learning algorithms exhibit different driving and testing performance in different scenarios, which underlines the need for their systematic comparative analysis. The benchmarking framework proposed in this paper facilitates such a comparison.
2021
-
 DeepOrder: Deep Learning for Test Case Prioritization in Continuous Integration TestingAizaz Sharif, Dusica Marijan, and Marius LiaaenIn 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), 2021
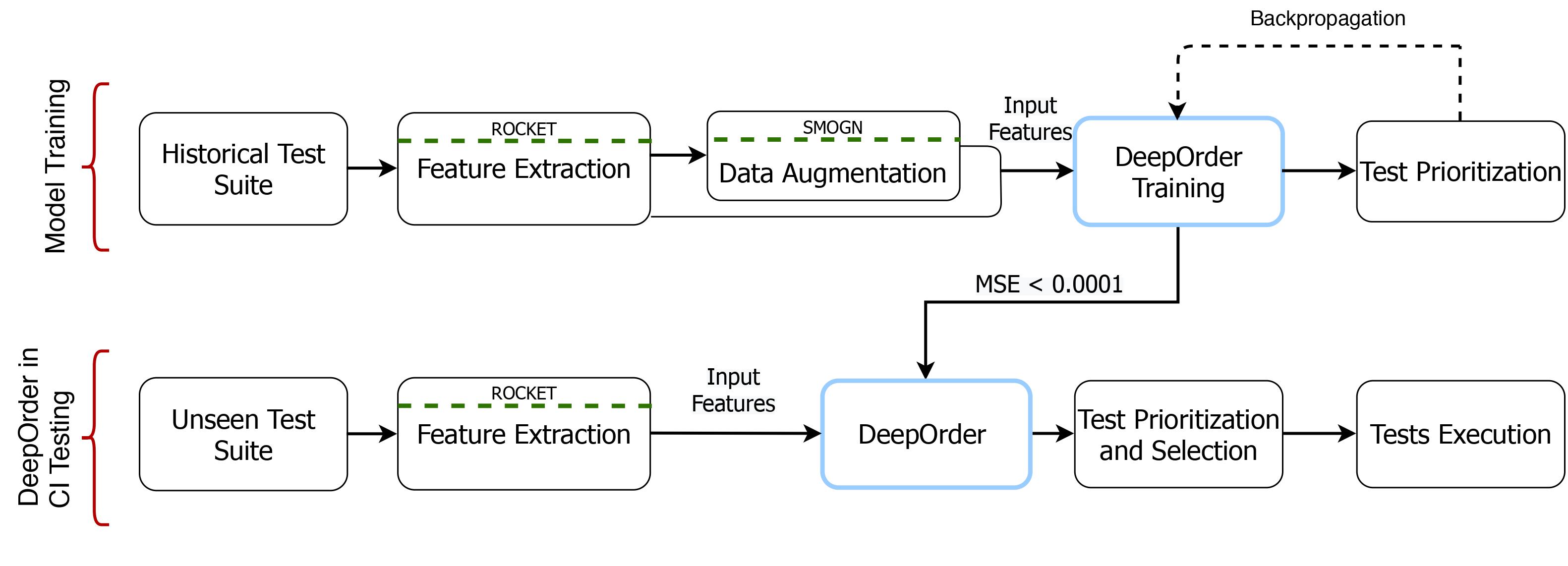
DeepOrder: Deep Learning for Test Case Prioritization in Continuous Integration TestingAizaz Sharif, Dusica Marijan, and Marius LiaaenIn 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), 2021Continuous integration testing is an important step in the modern software engineering life cycle. Test prioritization is a method that can improve the efficiency of continuous integration testing by selecting test cases that can detect faults in the early stage of each cycle. As continuous integration testing produces voluminous test execution data, test history is a commonly used artifact in test prioritization. However, existing test prioritization techniques for continuous integration either cannot handle large test history or are optimized for using a limited number of historical test cycles. We show that such a limitation can decrease fault detection effectiveness of prioritized test suites. This work introduces DeepOrder, a deep learning-based model that works on the basis of regression machine learning. DeepOrder ranks test cases based on the historical record of test executions from any number of previous test cycles. DeepOrder learns failed test cases based on multiple factors including the duration and execution status of test cases. We experimentally show that deep neural networks, as a simple regression model, can be efficiently used for test case prioritization in continuous integration testing. DeepOrder is evaluated with respect to time-effectiveness and fault detection effectiveness in comparison with an industry practice and the state of the art approaches. The results show that DeepOrder outperforms the industry practice and state-of-the-art test prioritization approaches in terms of these two metrics.
2019
- Android malware detection through generative adversarial networksMuhammad Amin, Babar Shah, Aizaz Sharif, and 3 more authorsTransactions on Emerging Telecommunications Technologies, 2019
Mobile and cell devices have empowered end users to tweak their cell phones more than ever and introduce applications just as we used to with personal computers. Android likewise portrays an uprise in mobile devices and personal digital assistants. It is an open-source versatile platform fueling incalculable hardware units, tablets, televisions, auto amusement frameworks, digital boxes, and so forth. In a generally shorter life cycle, Android also has additionally experienced a mammoth development in application malware. In this context, a toweringly large measure of strategies has been proposed in theory for the examination and detection of these harmful applications for the Android platform. These strategies attempt to both statically reverse engineer the application and elicit meaningful information as features manually or dynamically endeavor to quantify the runtime behavior of the application to identify malevolence. The overgrowing nature of Android malware has enormously debilitated the support of protective measures, which leaves the platforms such as Android feeble for novel and mysterious malware. Machine learning is being utilized for malware diagnosis in mobile phones as a common practice and in Android distinctively. It is important to specify here that these systems, however, utilize and adapt the learning-based techniques, yet the overhead of hand-created features limits ease of use of such methods in reality by an end user. As a solution to this issue, we mean to make utilization of deep learning–based algorithms as the fundamental arrangement for malware examination on Android. Deep learning turns up as another way of research that has bid the scientific community in the fields of vision, speech, and natural language processing. Of late, models set up on deep convolution networks outmatched techniques utilizing handmade descriptive features at various undertakings. Likewise, our proposed technique to cater malware detection is by design a deep learning model making use of generative adversarial networks, which is responsible to detect the Android malware via famous two-player game theory for a rock-paper-scissor problem. We have used three state-of-the-art datasets and augmented a large-scale dataset of opcodes extracted from the Android Package Kit bytecode and used in our experiments. Our technique achieves F1 score of 99% with a receiver operating characteristic of 99% on the bytecode dataset. This proves the usefulness of our technique and that it can generally be adopted in real life.
- Function Identification in Android Binaries with Deep LearningAizaz Sharif and Mohammad NaumanIn 2019 Seventh International Symposium on Computing and Networking (CANDAR), 2019
Application security support has become a preference for the enterprise as cybersecurity threats have transferred from the network perimeter to the application layer in modern years. To ensure that the software is secure, organizations must test it before purchase or deployment and identify any flaws that may expose the organizations to vulnerabilities. Binary code analysis is a new method for application security testing and is transforming software security. Binary analysis aids in many important applications including automatically fixing vulnerable software and malware detection. Plenty of research has been done to improve binary analysis using datasets related to different computer platforms, new compilers, and new optimization techniques. However, there is a vast majority of Android users and since it is an open-source platform it is equally vulnerable to similar attacks as well. In this research, we propose to implement deep neural networks to solve an essential yet difficult problem in binary analysis. We solve the problem of function boundary identification, a pivotal first step in a lot of binary analysis techniques. Neural networks have experienced a renewal in the past few years, achieving breakthrough outcomes in various fields such as object detection, language translation, and speech recognition. Yet no specific research has explored their utility in Android binary analysis. We exhibit that convolutional neural networks can identify functions in binaries with greater accuracy than the current state-of-the-art methods. Our model will be trained on a dataset of bytecode extracted from Android binaries. The proposed methodology is tested and evaluated on the Drebin Malware Dataset which contains Android Malware applications coming from various malware families. With the presented model, we achieved an overall precision of 0.75, recall of 0.79 and the f1 score of 0.76 in the testing phase.